Re: [R21.4] [AC] Re: [PATCH] Increasing the number of regex failure points.

>>>> "Adrian" == Adrian Aichner
<adrian(a)xemacs.org> writes:
Adrian> With this patch I still see the problem.
Adrian> I can reproduce the problem with
Thanks Adrian, I can reproduce the problem as well.
Looking a little deeper, it looks like the problem is related to the other
regex discussion that we had a month ago (the archives seem to be down at the
moment so I can't provide a link) and it seems to be that our regexp
implementation is breaking a heuristic that we picked up from GNU Emacs.
I'll spell out my reasoning so that someone else can see if I'm right.
The regex code contains a failure stack of finite size. Its size is
controlled by the variable re_max_failures, which I recently patched to
40000.
Unlike most stacks, this size is not the number of slots in the stack, but the
number of likely failure items on the stack. Each failure item can consume a
different number of slots but we take a guess and assume that a typical
failure consumes only MAX_FAILURE_ITEMS slots. This value is 20 for GNU Emacs
(under the name TYPICAL_FAILURE_SIZE) and 19 for us in non-debug builds.
The problem seems to be that this guess is wrong. Comparing the
implementation of PUSH_FAILURE_POINT with GNU Emacs, in their case a fixed 3
slots is used for each call. In our case we push a lot more onto the stack (I
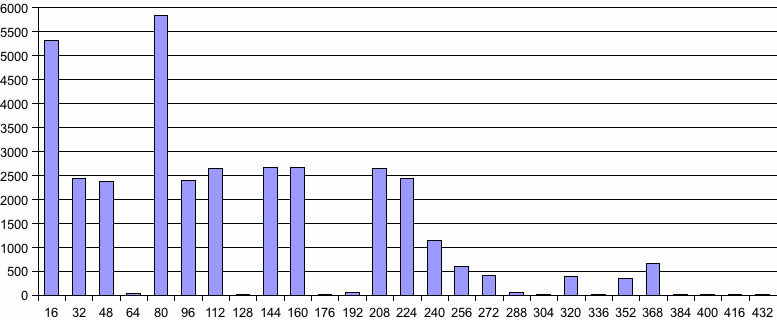
don't know why) and consume a variable number of slots. The graph below how
many requests for a certain number of slots (rounded up to the nearest 16) are
being made by PUSH_FAILURE_POINT() while next-error is trying to parse
Adrian's file.
As you can see, in some cases our guess is out be a factor of 20! Simply
we're running out of stack faster than GNU Emacs.
The patch that started the previous discussion fixed the problem by increasing
MAX_FAILURE_ITEMS to 40. I suggest that we conduct some more profiling to see
if it needs to be increased even further!
Malcolm
--
Malcolm Purvis <malcolmp(a)xemacs.org>
Attachments:
- histogram.gif (image/gif — 10.2 KB)
{kind=link}